
Overview
Machine Learning models are rapidly being adopted and implemented across organizations in a variety of use cases. Machine Learning implementation presents challenges in governance and control dueto the models being ‘black boxes’ and heavy dependence on training data. Model transparency, accountability, security and reusability are the key parameters in governing ML Models. Data Governance and Data security aspects are also to be addressed.
Following are the typical business and functional challenges encountered in ML Model Governance:
- Lack of a centralized governance platform to exchange model metadata (scope, expectations and dependencies) between the Business and Data Science teams
- ML-enabled applications typically call on a pipeline of interconnected models, often written by different teams using different languages and frameworks
- Lack of visibility into the source, quality and compatibility of the available training data
- Tracking of metadata and lineage of ML models and pipelines
- Data drift (change in model input data that leads to degradation of model performance)
- Data Scientists lacking access to the right dataset in a secured manner
- Lack of a shared inventory for model reuse and exchange between teams
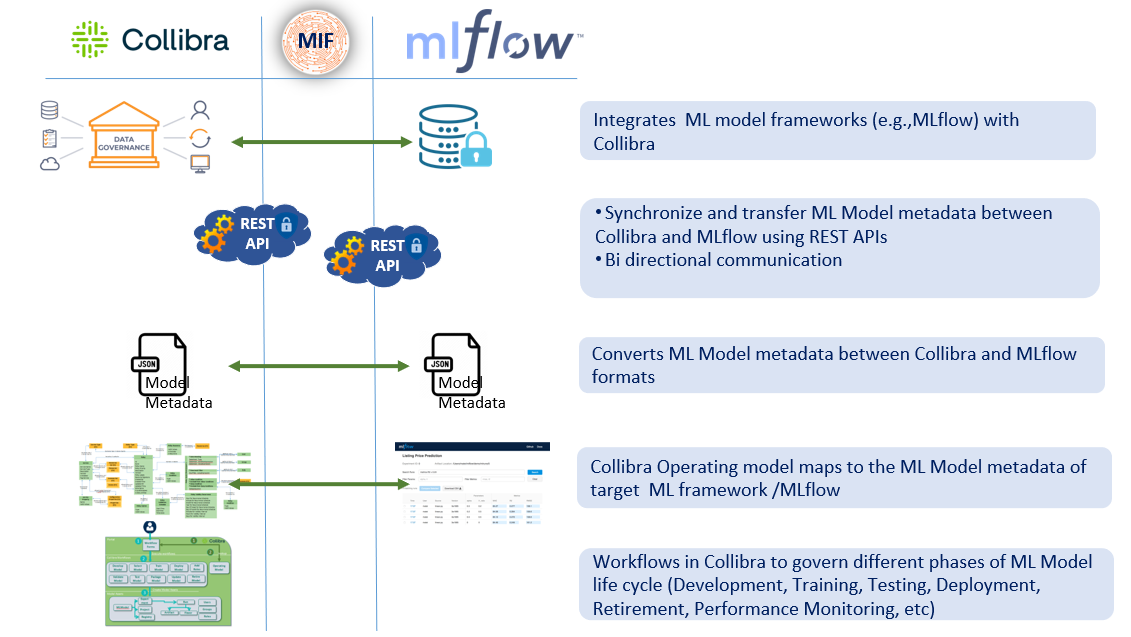
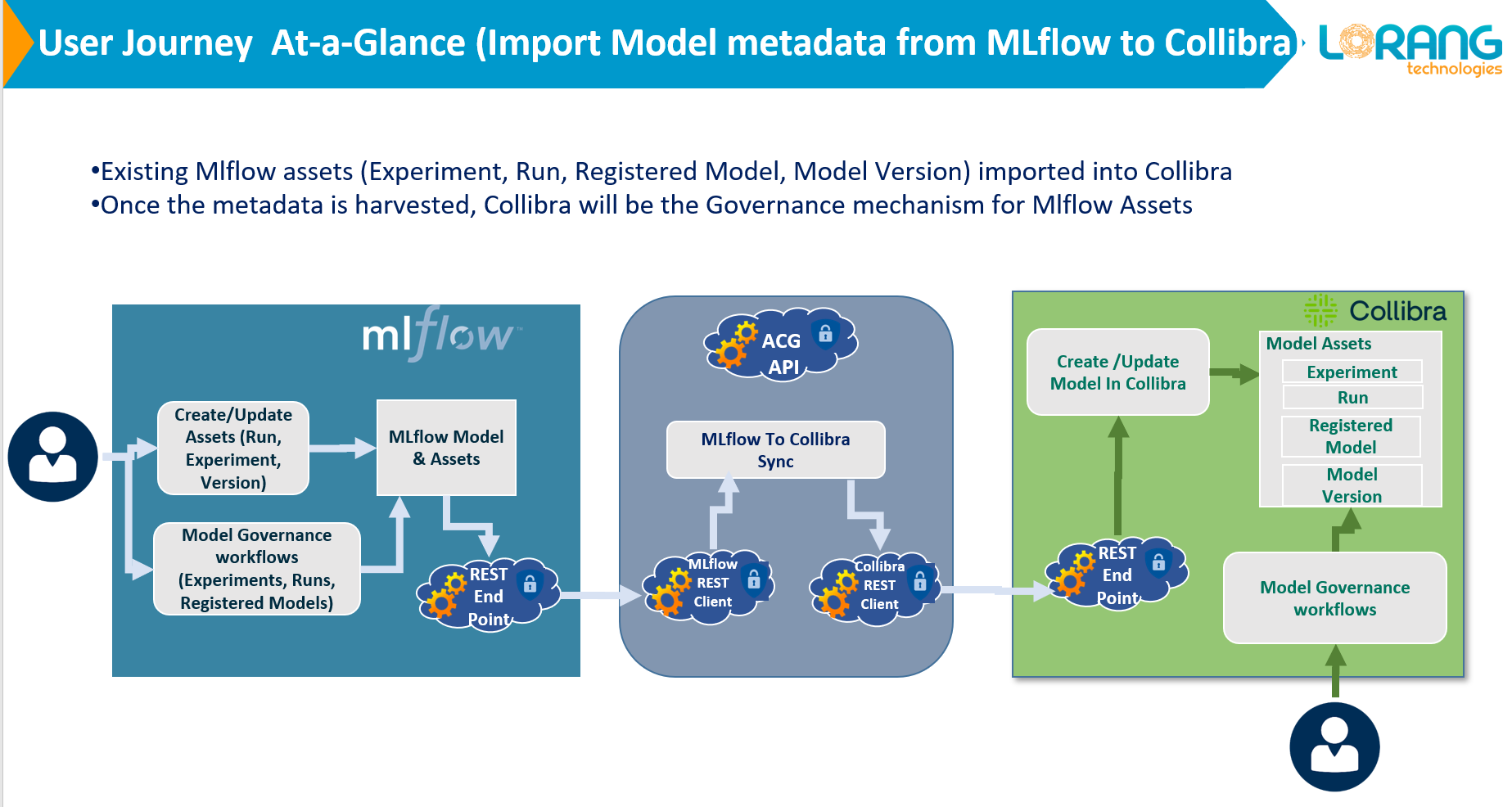
Model Governance (ModGov) provides a defined process to establish accountability for ML model lifecycle, and the training data for secure and efficient usage. It incorporates model governance, access control, model validation and selection in a well-defined manner. It tracks changes in Data and model dependencies and seamlessly integrates ML model lifecycle frameworks like MLFlow with Collibra (i.e., inputs, output, algorithms, pipelines and dependencies). Improves collaboration, detects model decay, provides more reliable and updated model metadata.
Features:
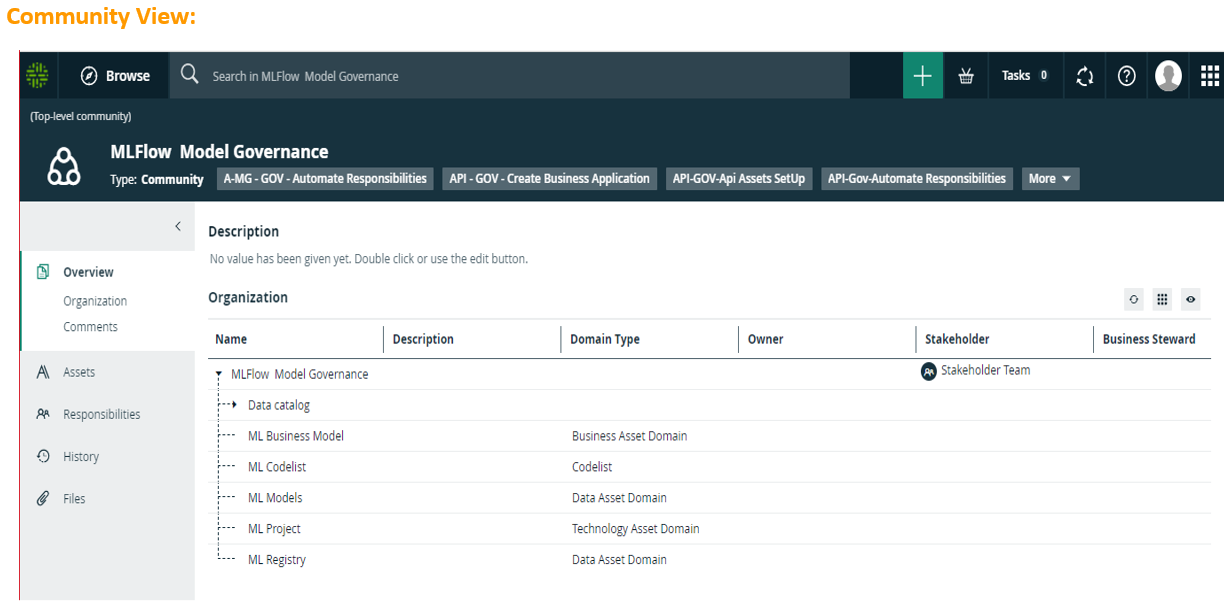
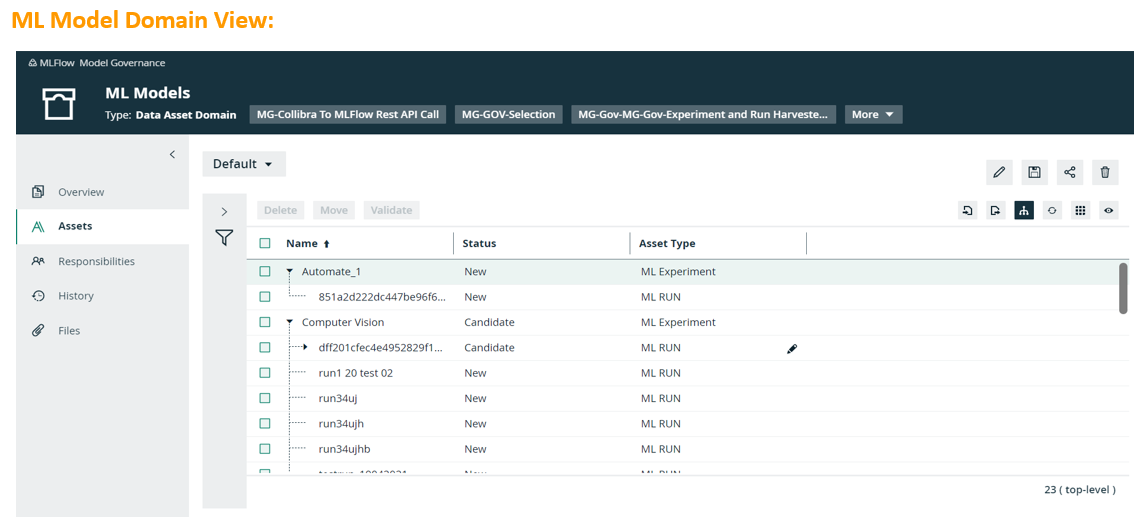
- Predefined Operating Model includes registered models, model runs, metrics, parameters, dataset etc.
- Centralized registry of models, model versions and Data with associated entitlements and access levels to ensure consistent, secure usage
- Maintains detailed inventory of all ML models along with business metadata and categorization
- Harvests technical metadata from model lifecycle frameworks like MLFlow
- Model validation process to review input Data, algorithms, parameters, dependencies, and output (metrics and artifacts)
- Automated Data drift detection process for the underlying dataset
- Guided process to verify the legitimacy and authoritativeness of Data sources, including external sources (e.g., open-source Data libraries, market Data providers and social media channels)
- Guided process to initiate model development with business alignment and success criteria
Enables model checkout by utilizing enhanced Collibra Data Basket experience
Media



Please send your questions directly to the vendor via:

 +1-732-314-1176
+1-732-314-1176